Как оператору выстроить инфраструктуру big data и сохранять $6 млн в год от фрода
Рынок аналитики для телекоммуникаций ежегодно растёт на 13,5% и будет расти до 2030 года, по
прогнозу Valuates Reports. При анализе больших массивов клиентских данных (или big data), операторы обнаруживают паттерны в поведении пользователей, которые можно использовать в бизнес-целях: улучшать эффективность рекламы, повышать ARPU, удерживать клиентов и бороться с мошенниками. Но как внедрить такую аналитику, чтобы сразу получить результат?
Показываем на опыте — Eastwind помог выстроить инфраструктуру для сбора, обработки и анализа больших данных одной из крупнейших телекоммуникационных компаний в СНГ. С нашим решением оператор не только научился обнаруживать фрод и предотвращать ежегодные финансовые потери, но также повысил доход от рекламы и уменьшил отток абонентов.
Ключевые результаты
Зачем операторам анализировать big data
Средний пользователь смартфона проводит в сети около 5 часов в день, по данным
Digital 2023 Global Overview Report. Каждым своим действием на устройстве человек генерирует онлайн-данные — когда звонит друзьям, отправляет сообщения, ищет товары в интернете или проводит время в соцсетях. Информация обо всех этих событиях поступает в базы телеком-операторов, которые обслуживают миллионы абонентов.
Изначально это «сырые» данные — сведения не структурированы и не обработаны, информация из разных источников хранится в различных базах, которые зачастую никак не связаны между собой. Чтобы получить из этого массива инсайты и прибыль, нужно собрать все данные в одном месте и запустить поиск паттернов с помощью AI/ML технологий.
Когда нужна отдельная платформа для работы с big data
Для анализа большого количества неструктурированных данных компании чаще всего разворачивают Hadoop кластер. Это программное обеспечение с открытым исходным кодом, которое позволяет хранить big data и реализовывать все необходимые вычисления.
Плюсы экосистемы Hadoop: бесплатный доступ, множество инструментов, масштабируемость и стоимость поддержки.
Минусы работы с Hadoop напрямую
- Экосистема открытая и отвечает не всем стандартам безопасности. В Hadoop отсутствует чёткое разделение ролей и прав доступа, а чувствительные данные могут оказаться в публичных лог-файлах.
- Devops- и дата-инженеры, а также аналитики компании должны обладать опытом работы со всеми инструментами Hadoop, знать языки баз данных всех источников. Таких специалистов мало на рынке, и они стоят дорого.
- Система уязвима — если внести ошибку в расчёте одной задачи или поставить несовместимую библиотеку, может прерваться работа всего аналитического алгоритма.
Построить инфраструктуру big data, используя преимущества Hadoop, но при этом устранив все сопутствующие минусы, позволяет платформа Eastwind DataFlow, которую мы и внедрили нашему клиенту.
Узнать больше про DataFlow
Формат проекта
Работа шла совместно с оператором и интегратором-партнёром. На старте проекта мы поставили следующие задачи на внедрение:
1.
Консолидировать все данные и упорядочить их хранение. Этот шаг стал основой для анализа big data и внедрения AI/ML технологий.
2.
Внедрить предиктивную аналитику по направлениям:
— Борьба с фродом.
— Предотвращение оттока абонентов.
— Эффективность cross-sell и upsell кампаний по ключевым продуктам.
Также клиент хотел самостоятельно развивать проект в будущем: интегрировать новые источники данных, создавать и дорабатывать ML-модели. Для этого в ходе проекта оператор сформировал команду штатных аналитиков данных — в этом ему тоже помогли специалисты Eastwind.
Таймлайн
Этап 1. Интеграция с источниками данных
До запуска проекта многие системы оператора работали независимо друг от друга. Что мы имели на старте:
— технологическая и географическая разрозненность источников данных (17 территориальных единиц),
— сложный ИТ-ландшафт, в который входили десятки платформ и решений разных вендоров,
— нереляционные и специфичные базы данных.
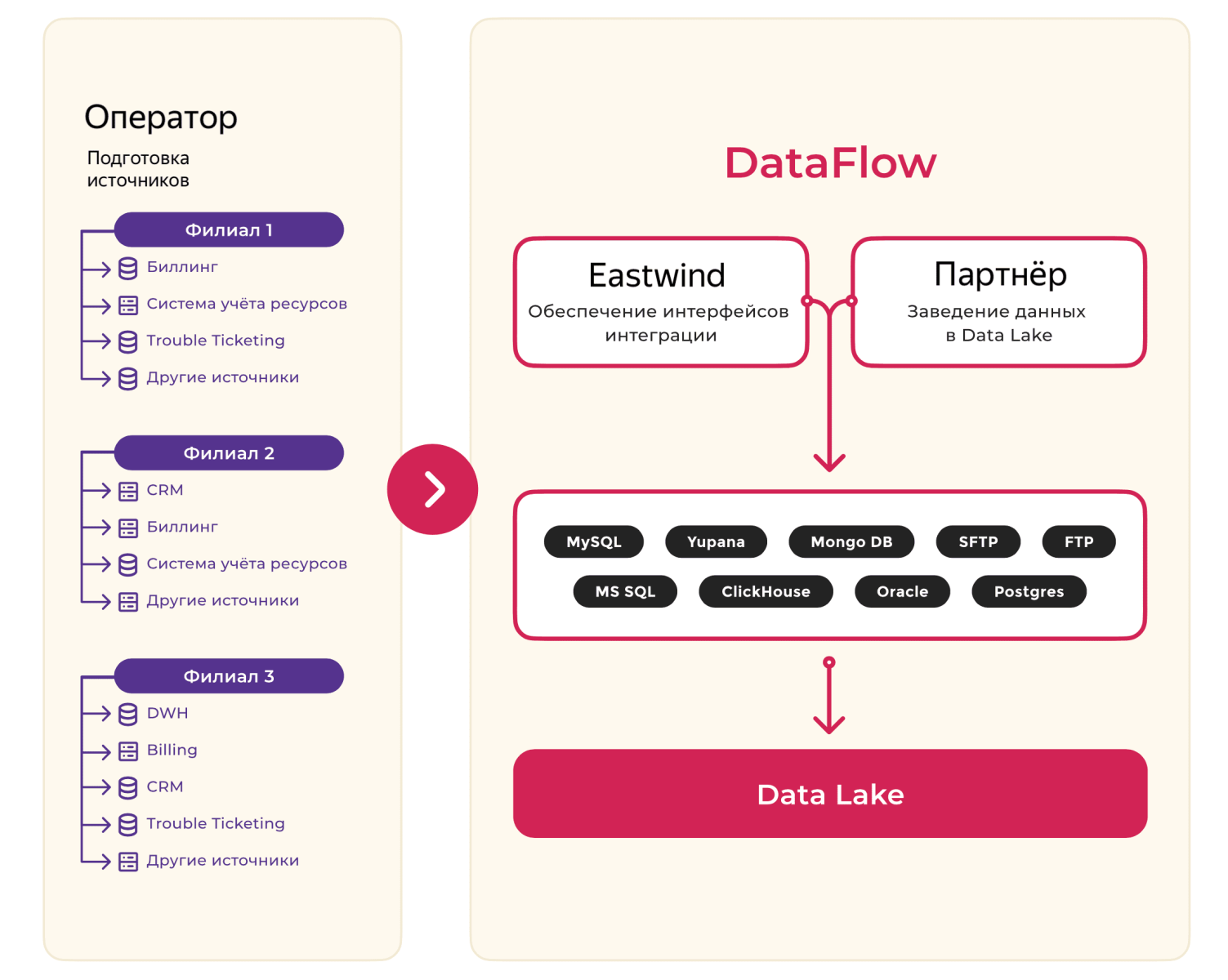
После того, как наша команда развернула и настроила Hadoop-кластер из 24 хостов, с общей ёмкостью 1.8 Пб, мы приступили к задаче по интеграции источников в единое озеро данных (data lake).
Для наполнения data lake Eastwind обеспечивал подключение необходимых источников данных, партнёр-интегратор заполнял данные на кластере и описывал регулярный импорт с помощью DataFlow, а оператор контролировал интеграцию данных на стороне источников и согласовывал методы загрузки данных и их описание.
В первую очередь, команда проекта интегрировала данные из внутренних информационных систем оператора: корпоративного хранилища, биллингов, систем учёта ресурсов и отчётности. Затем мы подключили и сторонние источники — например, государственный портал открытых данных.
Этап 2. Внедрение предиктивной аналитики
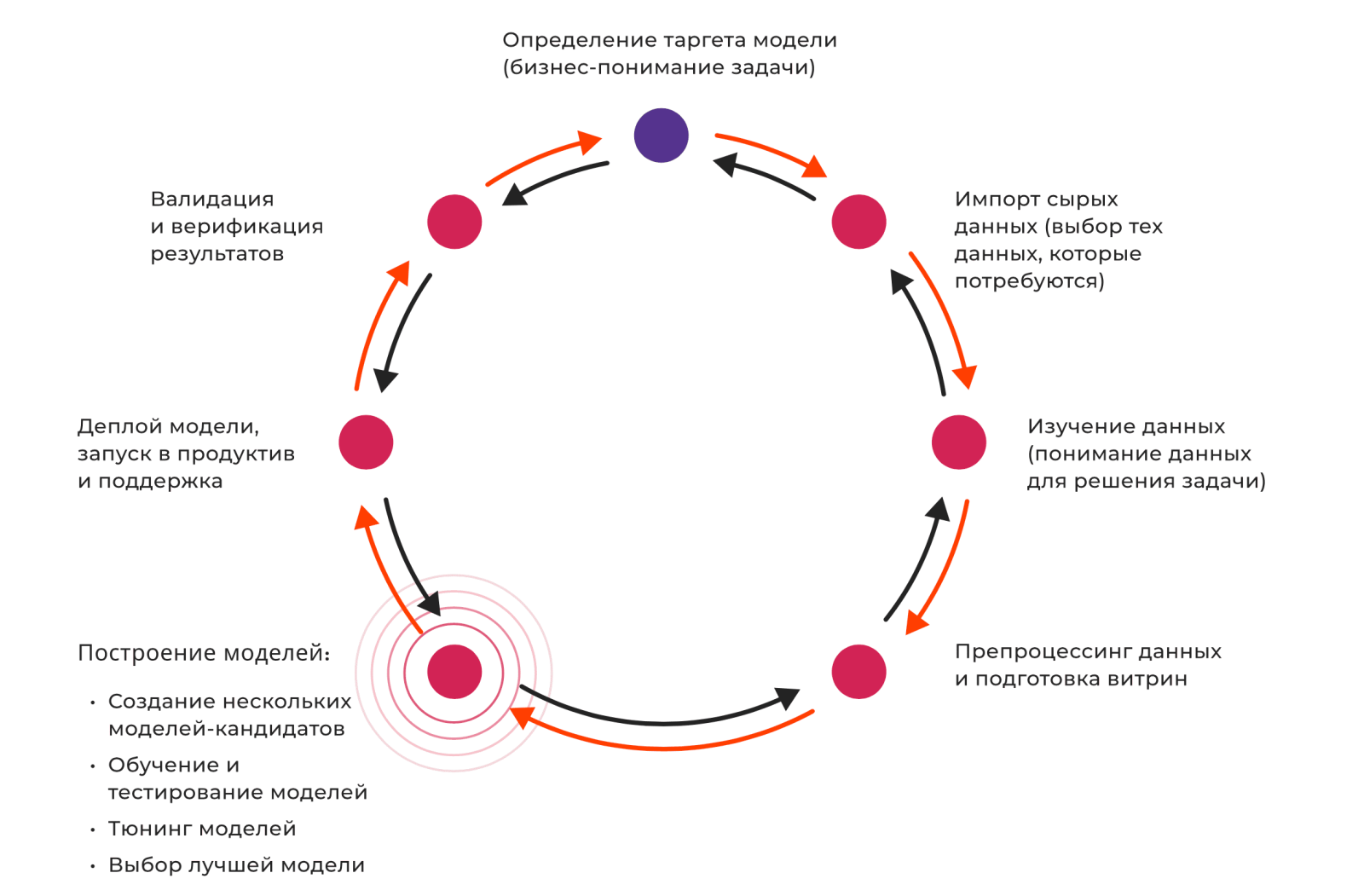
Когда проектная команда интегрировала достаточно источников данных, мы начали выстраивать бизнес-процесс проверки гипотез по ML-моделям.
Работа велась по трём направлениям: антифрод, предсказание оттока абонентов и построение модели NPTB (Next Product to Buy).
Антифрод-модели
Задачами этого направления было уменьшить финансовые потери оператора, снизить репутационные риски и предотвратить жалобы абонентов на мошенничество.
На этапе генерации гипотез проектная команда определила 20+ различных видов фрода и разработала 30+ аналитических моделей. По итогам первой проверки четыре из них эффективно смогли обнаруживать следующие мошеннические кейсы:
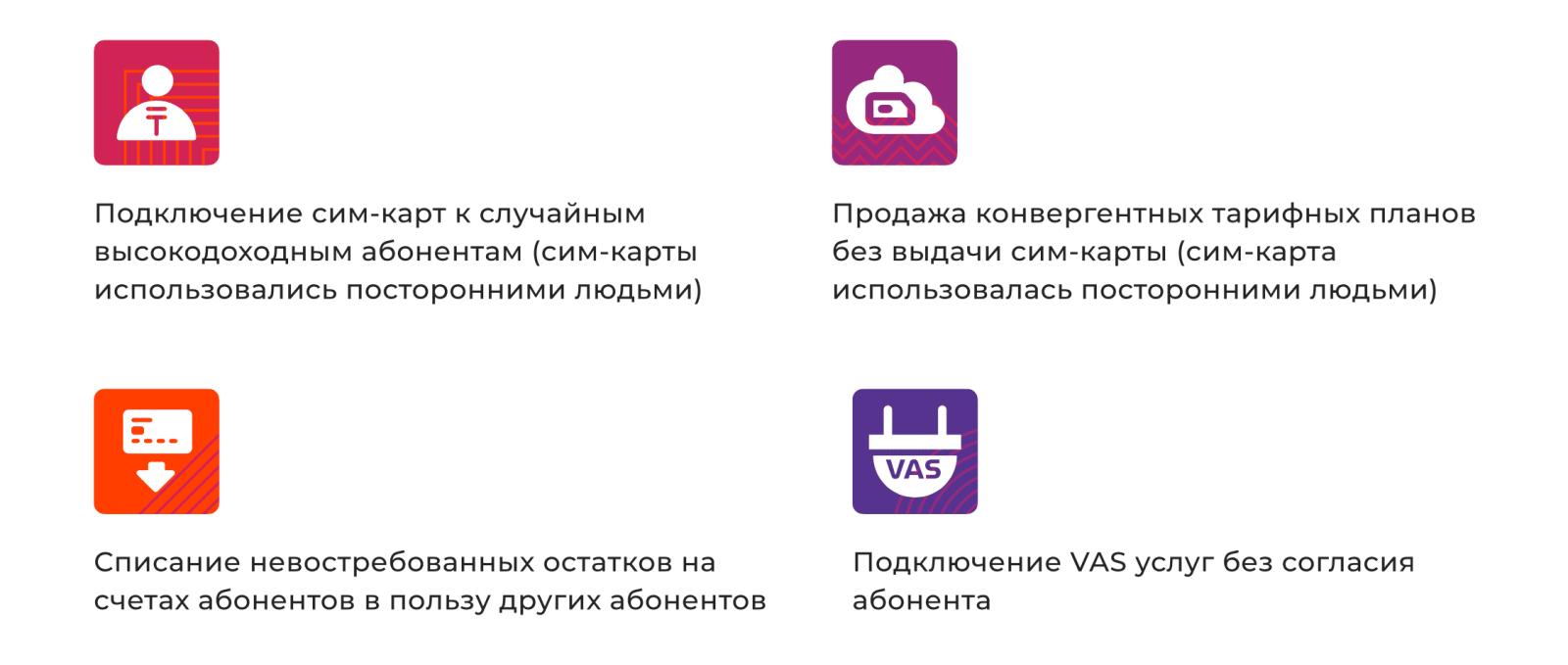
Внедрение аналитических моделей по борьбе с фродом снизило уровень сомнительной дебиторской задолженности, сняло фродулентные начисления и риски судебных издержек.
Директор департамента аналитики данных оператора
|
$ 1 100 000 в год
предотвращённых потерь — такой эффект от внедрения четырёх кейсов в первый год рассчитали в компании на исторических данных о мошенничестве за предыдущие годы
|
|
$ 6 000 000 в год
оценка предотвращённых потерь оператора после внедрения ещё 40 кейсов выявления фрода, которые аналитики сгенерировали и настроили после запуска всей инфраструктуры
|
Предсказание оттока абонентов
Задача этой модели — заранее обнаруживать клиентов, которые склонны сменить оператора. Один из множества индикаторов будущего отттока — недовольство абонента обслуживанием, тарифами или качеством связи. Поэтому, при разработке модели оттока проектная команда автоматизировала загрузку в DataFlow excel-таблиц с записями обращений абонентов по Whatsapp, Telegram и социальным сетям.
Также аналитический алгоритм адаптировали под все 17 регионов присутствия заказчика, в каждом из которых могли быть свои причины смены оператора (например, локальные конкуренты).
Всё это позволило постепенно улучшить результаты прогнозов. В начале работы точность модели составляла 0.12, а полнота — 0.13. Меньше, чем через год доработок точность выросла в четыре раза — 0.50; полнота увеличилась вдвое — 0.30. Это значит, что модель правильно делила на оттекающих и нет 50% абонентской базы, при этом обнаруживала 30% из всех клиентов, которые собираются уйти.

На второй год работы модели мы поставили цель добиться 70% точности и 50% полноты. Но даже сейчас видна кардинальная разница в работе с клиентской базой, по сравнению с периодом до развёртывания инфраструктуры big data. Раньше мы имели дело с абонентами, которые приходили в офис с целью отказаться от обслуживания, и только после этого его пытались убедить остаться. Сейчас же, 30% таких абонентов мы удерживаем превентивно. Это существенно повышает шансы переубедить оттекающих и снижает затраты на их удержание.
Директор департамента аналитики данных оператора
Модели Next Product to Buy
Изначально команда проекта реализовала NPTB-модели для двух core-продуктов — основных тарифных планов оператора. Специалисты создали ML-алгоритмы, которые анализировали профили абонентов, давно использующих выбранные продукты. Затем модели исследовали всю клиентскую базу и создавали списки пользователей, которые перейдут на продвигаемый тариф с наибольшей вероятностью.
Эти списки оператор передавал сотрудникам колл-центра для обзвона с предложением обновить тарифный план. Статистику покупок и отказов абонентов использовали для дообучения предиктивной модели. После достижения положительного эффекта по основным тарифам, в работу запустили дополнительные продукты и создали ещё шесть предиктивных моделей для cross- и upsell продаж.
|
$ 2 280 000
составил дополнительный доход от cross- и upsell продаж на базе моделей Next Product to Buy за первый год проекта
|
Общие результаты и развитие проекта
С внедрением DataFlow оператор получил готовую инфраструктуру для анализа клиентских данных. Теперь он может самостоятельно подключать любые источники информации, создавать предиктивные модели и быстро запускать их в продуктив. Заказчик также стал применять аналитику больших данных для анализа эффективности всей бизнес-деятельности. Например, запланировал внедрить кейсы предсказания выхода оборудования из строя, чтобы заранее принимать меры по обслуживанию. Что ещё вошло в планы развития:
- подключить 15 новых источников данных, в том числе неструктурированные текстовые диалоги из чатов поддержки оператора и итоги NPS-опросов;
- запустить кейсы внешней монетизации, например, определять наиболее выгодное расположение точек продаж;
- сделать апгрейд CVM-платформы для более гибких маркетинговых кампаний.
Возможности работы с big data в DataFlow
Платформа от Eastwind позволяет реализовать весь процесс работы с данными в одном окне:
— Подключать новые источники данных.
— Выбирать нужные сэмплы данных и проводить исследования.
— Строить аналитические модели и быстро запускать их в продуктив.
— Экспортировать данные потребителям платформы.
— Мониторить расчёты, обнаруживать ошибки и отслеживать качество моделей.
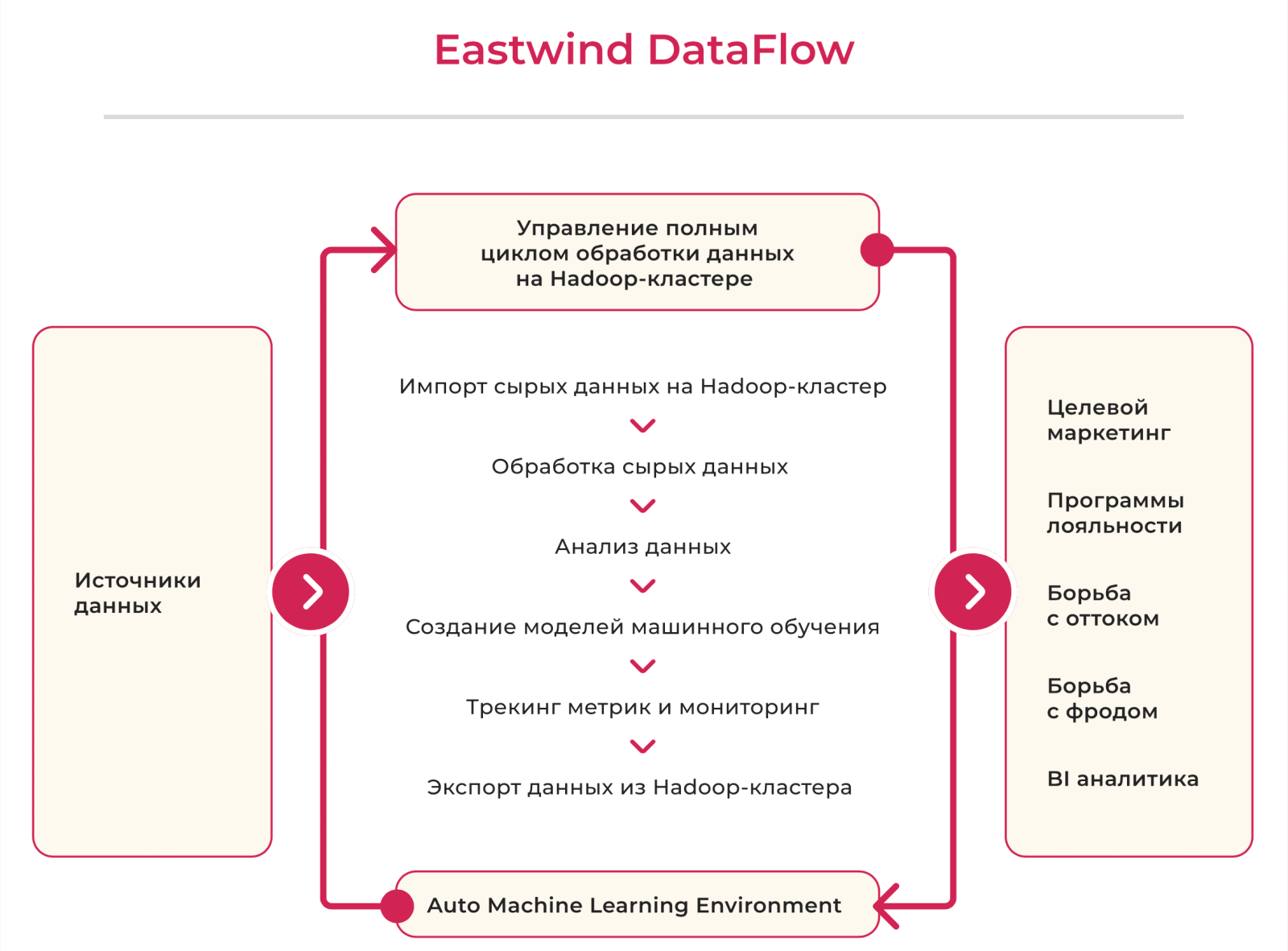
Платформа имеет преднастроенные интерфейсы работы с большинством баз данных, что упрощает и ускоряет процесс работы и снижает требования к пользователям решения. Также DataFlow обеспечивает высокий уровень безопасности данных — с ролевой моделью доступа, корпоративной аутентификацией и скрытием всей чувствительной информации, передаваемой в среде Hadoop.

.png)